
Методы вскрытия одноалфавитных систем (расшифровка)
|
При своей простоте в реализации одноалфавитные системы шифрования легко уязвимы. Определим количество различных систем в аффинной системе. Каждый ключ полностью определен парой целых чисел a и b, задающих отображение ax+b. Для а существует j(n) возможных значений, где j(n) - функция Эйлера, возвращающая количество взаимно простых чисел с n, и n значений для b, которые могут быть использованы независимо от a, за исключением тождественного отображения (a=1 b=0), которое мы рассматривать не будем. Таким образом получается j(n)*n-1 возможных значений, что не так уж и много: при n=33 в качестве a могут быть 20 значений( 1, 2, 4, 5, 7, 8, 10, 13, 14, 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), тогда общее число ключей равно 20*33-1=659. Перебор такого количества ключей не составит труда при использовании компьютера. Но существуют методы упрощающие этот поиск и которые могут быть использованы при анализе более сложных шифров. Частотный анализОдним из таких методов является частотный анализ. Распределение букв в криптотексте сравнивается с распределением букв в алфавите исходного сообщения. Буквы с наибольшей частотой в криптотексте заменяются на букву с наибольшей частотой из алфавита. Вероятность успешного вскрытия повышается с увеличением длины криптотекста. Существуют множество различных таблиц о распределении букв в том или ином языке, но ни одна из них не содержит окончательной информации - даже порядок букв может отличаться в различных таблицах. Распределение букв очень сильно зависит от типа теста: проза, разговорный язык, технический язык и т.п. В методических указаниях к лабораторной работе приведены частотные характеристики для различных языков, из которых ясно, что буквы буквы I, N, S, E, A (И, Н, С, Е, А) появляются в высокочастотном классе каждого языка. Простейшая защита против атак, основанных на подсчете частот, обеспечивается в системе омофонов (HOMOPHONES) - однозвучных подстановочных шифров, в которых один символ открытого текста отображается на несколько символов шифротекста, их число пропорционально частоте появления буквы. Шифруя букву исходного сообщения, мы выбираем случайно одну из ее замен. Следовательно простой подсчет частот ничего не дает криптоаналитику. Однако доступна информация о распределении пар и троек букв в различных естественных языках. Криптоанализ, основанный на такой информации будет более успешным.Таблица: средние частоты распределения букв в русском и английском алфавите:
Хотя нет таблицы, которая может учесть все виды текстов, но есть вещи общие для всех таблиц, например, в английском языка буква E всегда возглавляет список частот, а T идет на второй позиции. A и O почти всегда третьи. Кроме того девять букв английского языка E, T, A, O, N, I, S, R, H всегда имеют частоту выше, чем любые другие. Эти девять букв заполняют примерно 70% английского текста. Ниже приведены соответствующие таблицы частот для различных языков (немецкий, французский, итальянский, финский).  Таблица частот биграммТаблица частот биграмм отражает количество повторений в тексте определенных пар букв (биграмм).Метод полосок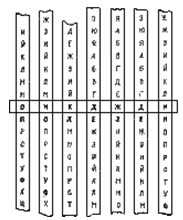 Для шифра Цезаря имеется более простой способ расшифровки - так называемый метод полосок. На каждую полоску наносятся по порядку все буквы алфавита. В криптограмме берется некоторое слово. Полоски прикладываются друг к другу так, чтобы образовать данное слово. Двигаясь вдоль полосок находится осмысленное словосочетание, которое и служит расшифровкой данного слова, одновременно находится и величина сдвига. Добавил: COBA (12.10.2010) | Категория: Защита информации Просмотров: 15351 | Загрузок: 0 | Рейтинг: 5.0/2 | | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарии (0) | |